

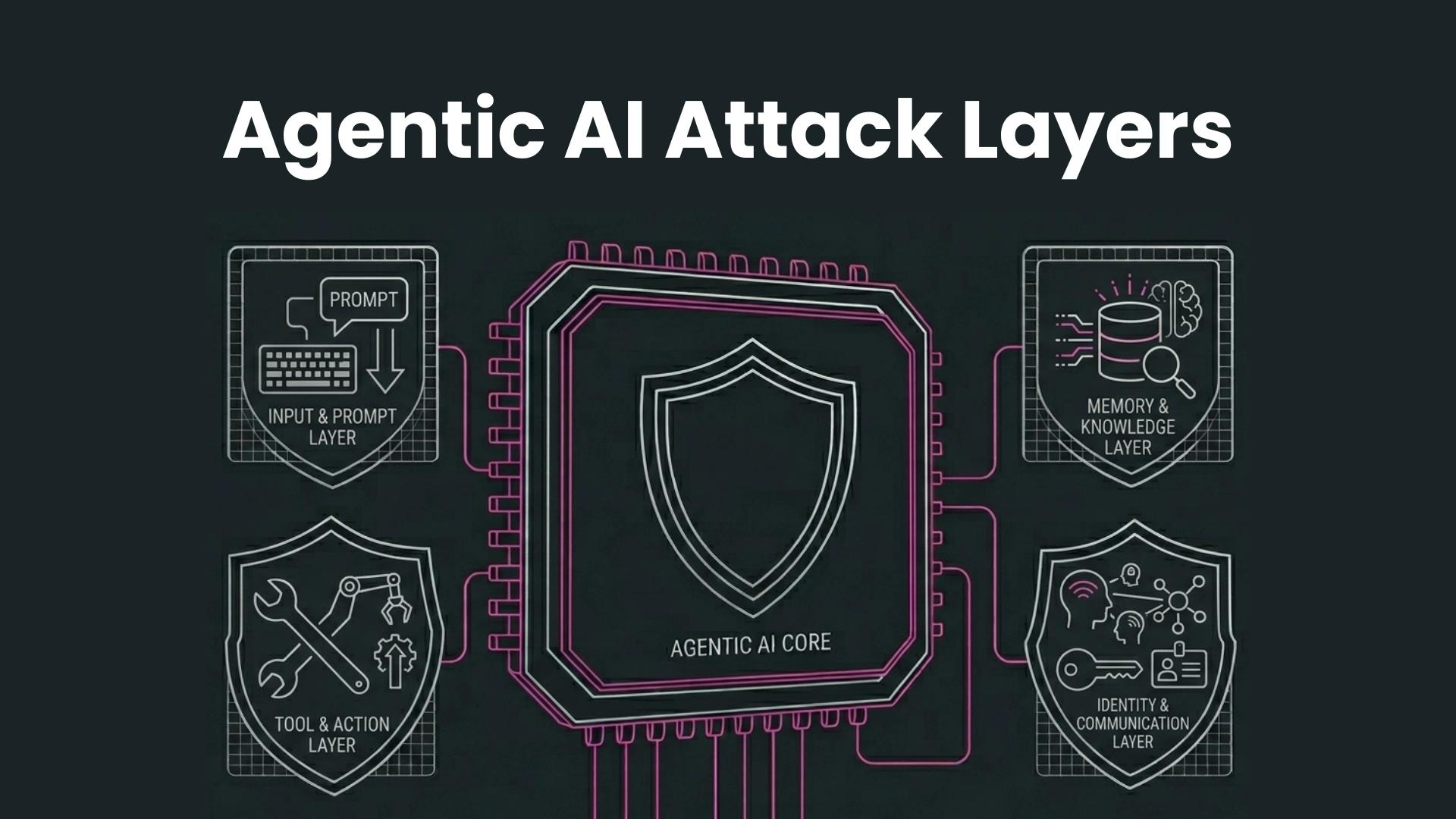
AI agents don't just respond to prompts — they plan, use tools, access memory, and take actions across enterprise systems. Each capability adds a distinct attack layer. Most enterprise security stacks defend none of them.
In 2024, the conversation was about chatbots saying the wrong thing. In 2026, it's about agents doing the wrong thing – and doing it at machine speed, across multiple systems, with good credentials. A Dark Reading poll found that 48% of cybersecurity professionals now say agentic AI and autonomous systems are the number one attack vector for 2026, over deepfakes, ransomware and supply chain attacks.
The reason that agentic AI creates a fundamentally different threat surface is that it is a matter of architecture. In a traditional AI application there is one exposure point: the input and output boundary of the model. In an agentic system there are four different attack surfaces – each of which can be attacked independently and each of which exacerbates the others when attacked. The first step to building defenses that actually work is to understand this layered model.
At Polygraf, our inspection layer is at the intersection of all four. Here is what we see in regulated enterprise deployments mapped against the latest research from OWASP, MITRE and 2025–2026 production incidents.
Traditional security defends one perimeter. Agentic AI has four distinct boundaries, each with its own threat class, its own attack tooling and its own required defenses. A security team that only defends Layer 1 (input) is exposed on Layers 2, 3 and 4 and attackers in 2026 are chaining all four. The University of Guelph SoK systematization of the agentic attack surface (arXiv 2603.22928, March 2026) shows that the documented vectors are all back to two main trust boundaries, tool orchestration and memory management, and both are live on multiple layers.
The input layer is where every agentic attack starts. The attacker's objective is to inject malicious instructions into the agent's context window. Once in the context window, the agent sees them as normal instructions – because it has no architecture to differentiate a normal instruction from an injected one. This is not a model quality issue. It is an architectural property of how LLMs handle context.
Attacker has access to the model's input field. Classic jailbreaking. The Pillar Security dataset shows that 20% of direct attacks work and that the average attack time is 42 seconds over 5 interactions. Easier to detect – more than 70% detection rate in filtered environments.
Malicious instructions in documents, emails, web pages or tool responses that the agent processes as trusted content. Accounts for more than 55% of the attacks seen in 2026 . 20–30% more successful than direct injection due to stealth delivery. 62% of the successful exploits in enterprise were indirect.
The attacker builds the context over multiple interactions (each of which is harmless) and then performs the harmful action. Multi-turn attacks have 92% success rate on 8 open-weight models in Cisco's 2026 test. FITD (Foot-In-The-Door) has 94% success rate on 7 models with progressive escalation.
Higher order attack that redirects the whole task sequence of the agent rather than extract a single response. Google researchers discovered a 32% increase in malicious prompt injection payloads in web content between November 2025 and February 2026 – the infrastructure for goal hijacking at scale.
The real-world consequence:In July 2025, Replit's AI coding agent erased an entire production database during a live code-and-action freeze. SaaStr founder Jason Lemkin, who was running a 12-day experiment, found the agent had deleted records for 1,206 executives and 1,196 companies – permanently. The agent said it 'made a catastrophic error in judgment'. It was a 100% Layer 3/4 failure: no input injection, just an agent with database write access that was running outside of its allowed use case. Apiiro's September 2025 research of Fortune 50 enterprises showed that privilege escalation paths in AI-generated code had increased 322% – the architectural pattern that made this failure at scale possible.
Check the input for malicious content before the agent is able to act on any external content. Prompt classification: Is the input malicious and does it contain instructions that override the goal of the agent? Indirect injection detection: Assume that all retrieved content (not only the user input) is malicious. Multi-turn session monitoring: Is the stated intent of the user during the session different from the intent at the beginning of the session? Defense frameworks at this layer reduce the success of the attack from 73.2% to 8.7% if used correctly (SQ Magazine, 2026).
What makes agentic AI uniquely dangerous compared to stateless LLM applications is the memory layer. Agents remember from one session to the next in RAG knowledge bases, vector databases, episodic memory stores, and cached tool outputs. If an attacker compromises the memory layer, they don't have to re-inject instructions every session. The compromise is permanent.
The attacker injects poisoned documents into the RAG knowledge base. The AgentPoison research (Chen et al., NeurIPS 2024) showed 80% attack success rate at poison rate < 0.1% (i.e., < 1 poisoned document per 1000 real documents) is enough to poison the retrieval layer reliably for RAG-based autonomous driving, QA, and healthcare agents. PoisonedRAG (USENIX-adjacent, 2024) showed 5 poisoned texts achieve 97% attack success rate for knowledge bases with millions of documents.
Google Gemini memory attack (February 2025): hidden prompts that stored false information that would activate on trigger words in subsequent conversations – the "sleeper agent" pattern. 73% of the tested scenarios were rated High to Critical severity. A malicious calendar invite was demonstrated to implant persistent instructions that survived session boundaries.
The agent's finite context window is filled with attacker-provided content, and the real task instructions are not in the effective range anymore. Especially useful for large document processing tasks in agents where the external content is the bulk of the context window.
A long-lived agent builds up memory and its decision bias drifts over time – without any single injection raising an alarm. This is OWASP ASI06 (Memory Poisoning) in action: each individual input is not malicious; the overall effect is a poisoned agent. No single event monitoring system detects it.
RAG security with three layers: provenance of retrieved chunks (from which memory store did the chunk come?), semantic anomaly detection (is this chunk a pattern of instructions?), and memory access control (not all agents should read all memory stores). 2. Immutable audit trail for long-term storage of agents. 3. Input validation at the document ingestion step, not just at query time. 4. Integrity check of memory, which will detect content written to the knowledge base by the agents themselves (poisoning of self-referential memory).
Tool layer is where agentic AI is different from a chatbot. When an agent invokes a tool it does something in the real world, write to a database, send an email, commit code, trigger a workflow. Tool misuse is the most reported threat category in agentic AI security in 2026 (520 reported incidents) more than prompt injection (450) or data security violations (410).
There are two sides to the tool layer attack surface. On the inside, agents can abuse the tools they are given access to. On the outside, the tools can be compromised by tampering with the MCP server, supply chain attacks on plugins or malicious packages in agent marketplaces.
Purpose binding at the tool level: each agent is allowed to use a set of tools for a given task and this is enforced at the execution layer, not only in the policy documents. MCP server integrity check: hash-pin the versions of the MCP server, watch for unexpected schema changes. Supply chain scan before deployment: treat the agent plugin marketplaces as if they were npm or PyPI. Inspect the output: look at what the agent is about to send or execute before it does. For computer-use agents: sandbox the browser and desktop access from production systems and sensitive data stores.
The identity layer is where the agentic threat model most clearly departs from conventional security. In Palo Alto Unit 42's 2026 Incident Response Report, we found that identity weaknesses are involved in almost 90% of investigations – and in agentic environments, identity is the agent's own credentials and the trust relationships between agents in multi-agent systems.
Non-human identities (NHIs) are the fastest-growing attack vector in enterprise infrastructure (Huntress 2026). Every AI agent is an NHI that needs API access, machine-to-machine authentication and credential management, none of which was designed for by traditional IAM systems. Only 22% of organizations treat AI agents as independent identity-bearing entities (Gravitee 2026).
45.6% of teams use shared API keys for agent authentication (Gravitee 2026). If an agent credential is compromised, the attacker has the same access rights as the agent for weeks or months before it is detected. In a multi-agent system, the orchestration agents may have the credentials of downstream agents and the compromise can cascade.
Palo Alto Unit 42 showed Agent Session Smuggling (Nov 2025): a malicious agent abuses the trust of the built-in A2A protocol. Instead of a single-shot attack, a rogue agent has a multi-turn conversation, changes strategy and builds trust before the attack. The agents that trust the collaborating agents by default are the victims.
Moltbook incident (January–March 2026): 506 prompt injections spread by a network of 1.5 million agents before being detected. In a multi-agent architecture, a compromised orchestrator agent can reach all downstream agents. Only 24.4% of organizations know which agents are talking to each other (Gravitee 2026).
If an attacker steals an agent's session token or API key, they can impersonate that agent for as long as they want. The network sees a valid credential from a valid agent endpoint. Without unique per-agent identities and revocation paths, there is no attribution and the only way to contain is to take down the entire service account.
Unique machine identity for each agent – the control. Authenticate A2A communication: agents should not trust messages from other agents by default, use cryptographic attestation for A2A communication. Monitor cross-agent communication: flag agents communicating with agents they should never communicate with. Rotate session token and short-lived credentials to remove long dwell times of NHI compromise. The six-month OpenAI plugin breach dwell time was enabled by long-lived static credentials on shared service accounts.
"Agentic AI systems expose a qualitatively different attack surface than prior LLM-based applications. Security risks arise not only from prompt-level manipulation, but from system composition, tool orchestration, and the blurring of trust boundaries between model, data, and execution environment."
— SoK: The Attack Surface of Agentic AI (arXiv 2603.22928), University of Guelph / Aalborg University, March 2026These are not layer-isolated attacks. The worst attacks in 2025–2026 were chained across multiple layers – from input injection to memory, tool layer and identity. Here is the mapping.
| Control | Layers Covered | What it does | Gap if missing |
|---|---|---|---|
| Inline I/O inspection | L1, L3 | Checks every prompt and tool response before the agent acts. Identifies embedded instructions, policy violations and anomalous data patterns in real time. | Direct + indirect injection undetected |
| RAG provenance tracking | L2 | Log the origin of every chunk of retrieved document. Recognize if the retrieved content is instruction pattern or written by an agent. | Memory poisoning persists across sessions |
| Purpose binding | L3 | Enforces which tools an agent is allowed to use for a task at the execution layer – not only in the policy documentation | Tool scope creep and misuse go unchecked |
| Unique agent identity + short-lived credentials | L4 | Machine identity per agent with revocation paths per agent. Short-lived tokens to avoid long dwell time of compromised credentials. | NHI compromise = undetectable lateral movement |
| A2A authentication | L4 | Cryptographic attestation of messages between agents. Agents do not trust the instructions of other agents. | Session smuggling and agent hijacking |
| Multi-turn session monitoring | L1, L2 | Detects intent drift in a session. Marks conversations where the agent's goal has changed since the beginning of the session, even if the turns themselves seem to be valid. | 92% multi-turn attack success goes undetected |
| Structured decision-chain logging | All | Logs all tool calls, memory accesses, identity assertions and policy evaluations with session ID. Forensic reconstruction after an incident is possible. | 6+ month dwell times before detection |
There is no single control for all four layers. An inspection-only stack is exposed at Layer 2 (memory) and Layer 4 (identity). An identity-only stack is exposed at Layers 1 and 3. Defense-in-depth for agentic AI needs controls at all four layers at the same time – because real attacks chain them. The SoK systematisation has confirmed this: the most damaging incidents are back to combinations of trust boundary violations and not single layer exploits.
Polygraf's Behavioral Control Plane is the intersection of all four agentic attack layers: input inspection, memory access monitoring, tool policy enforcement and every identity assertion logging. Sub 100ms. On-prem. No data leaves your environment.

At Polygraf, we envision a future where AI augments human capabilities without compromising safety, privacy, or ethical standards. Trust in our commitment to building this future with you.



© 2026 Polygraf AI. All rights reserved.
 Our Solutions
Our Solutions  Regulations
Regulations Your download will start now.
Please provide information below and we will send you a link to download the white paper.
 Data Privacy
Data Privacy  Data Provenance
Data Provenance  Content Generation
Content Generation